

在当今数字化的时代,数据如同隐藏在网络世界中的宝藏,而 Python 爬虫则是挖掘这些宝藏的有力工具。然而,在进行爬虫操作时,我们常常会遇到各种限制和挑战。这时,代理服务器就成为了 Python 爬虫的得力助手。
一、为什么需要代理服务器?
在网络世界中,许多网站为了防止恶意爬虫的攻击,会对频繁访问的 IP 地址进行限制。如果我们使用同一个 IP 地址进行大量的爬虫操作,很可能会被目标网站识别并封锁。而代理服务器可以为我们提供不同的 IP 地址,让我们能够绕过这些限制,继续进行数据采集。
此外,代理服务器还可以提高爬虫的效率。通过使用多个代理服务器,我们可以同时从不同的 IP 地址发起请求,加快数据采集的速度。
二、如何选择合适的代理服务器?
1、稳定性
选择一个稳定的代理服务器至关重要。不稳定的代理服务器可能会频繁掉线,导致爬虫中断,影响数据采集的进度。我们可以通过查看代理服务器的评价和口碑,选择那些被广泛认可的稳定代理服务提供商。2、速度
代理服务器的速度也是一个重要的考虑因素。如果代理服务器的速度过慢,会大大降低爬虫的效率。我们可以通过测试不同代理服务器的响应时间,选择速度较快的代理服务。
3、匿名性
为了保护我们的隐私和安全,我们需要选择具有较高匿名性的代理服务器。这样可以防止目标网站识别我们的真实 IP 地址,降低被封锁的风险。
三、如何在 Python 爬虫中使用代理服务器?
1、使用 requests 库
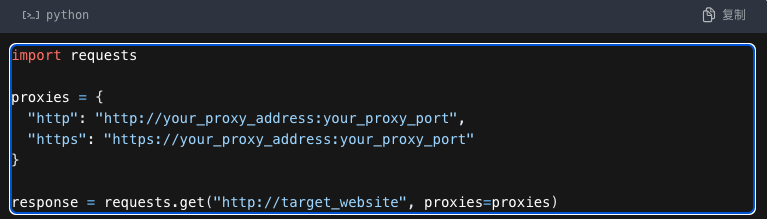
requests 是 Python 中一个非常流行的 HTTP 库,它支持使用代理服务器进行请求。我们可以通过设置 proxies 参数来指定代理服务器的地址和端口。
例如:
2、使用 Scrapy 框架
Scrapy 是一个强大的 Python 爬虫框架,它也支持使用代理服务器。我们可以在 settings.py 文件中设置 PROXY 变量来指定代理服务器的地址。
例如:
![]()
然后,在爬虫的代码中,可以通过以下方式使用代理服务器:

四、注意事项
在使用代理服务器进行 Python 爬虫时,我们需要注意以下几点:
1、遵守法律法规
在进行爬虫操作时,我们必须遵守法律法规,不得用于非法目的。同时,也要尊重目标网站的使用条款和隐私政策。
2、控制访问频率
即使使用了代理服务器,我们也不能过于频繁地访问目标网站,以免对目标网站造成过大的负担。我们可以通过设置合理的访问间隔时间,控制爬虫的访问频率。
3、定期更换代理服务器
为了避免被目标网站识别,我们可以定期更换代理服务器,使用不同的 IP 地址进行爬虫操作。
总之,代理服务器是 Python 爬虫的重要工具,它可以帮助我们绕过限制、提高效率、保护隐私。但是,在使用代理服务器时,我们需要选择合适的代理服务器,并遵守法律法规和道德规范,以确保爬虫操作的合法性和可持续性。