

在数字化浪潮席卷全球的今天,网络爬虫已成为数据海洋中不可或缺的探索者。它们默默穿梭于互联网的脉络之间,为各行各业输送着宝贵的数据养料。然而,在这场数据盛宴中,爬虫IP犹如它们的隐形斗篷,其重要性不言而喻。本文将深入剖析爬虫IP的奥秘,并分享实战中的策略与技巧。
一、爬虫IP的奥秘揭示 爬虫IP的定义与本质
爬虫IP,简而言之,就是网络爬虫在执行数据采集任务时所采用的IP地址。想象一下,当你驾驶一艘数据采集的“潜水艇”在网络海洋中航行时,你的“潜水艇”标识(即IP地址)就是你在这个世界中的身份证明。如果你的“潜水艇”频繁地使用同一个身份访问某个网站,那么它很可能会被识别并遭到拒绝访问的待遇。因此,更换不同的身份(即使用不同的爬虫IP)成为了爬虫生存与发展的关键。
爬虫IP的多样性分类爬虫IP的世界纷繁复杂,根据不同的标准可以划分为多种类型。从匿名程度来看,我们可以将其分为透明代理IP、普匿代理IP和高匿代理IP三大类。透明代理IP如同穿着透明斗篷的侦探,虽然能够隐藏一部分身份,但真实面目仍易被发现;普匿代理IP则像是穿着半透明斗篷的侦探,能够隐藏大部分身份,但仍有一定的风险;而高匿代理IP则是名副其实的隐形斗篷,能够完全掩盖爬虫的真实身份,是爬虫程序的首选。
此外,从时效性的角度来看,爬虫IP还可以分为短效爬虫IP和长效爬虫IP。短效爬虫IP如同烟花般绚烂而短暂,它们适合用于需要快速更换IP以应对封锁的场景;而长效爬虫IP则如同老树盘根般稳定可靠,适用于对稳定性要求较高、访问频率相对较低的爬虫任务。
二、爬虫IP的实战应用 突破访问限制的利器
在互联网的广阔天地中,许多网站为了维护自身的安全和秩序,会对同一IP的访问频率进行限制或对特定地区的IP进行封锁。这时,爬虫IP就成为了突破这些限制的利器。通过伪装成不同地区的IP地址,爬虫可以绕过这些限制,顺利访问目标网站并获取所需数据。
提高采集效率的加速器
在数据采集的战场上,效率往往决定了胜负。使用爬虫IP可以帮助爬虫程序避免被目标网站识别为爬虫行为而被封锁的命运。通过不断更换IP地址,爬虫可以持续稳定地进行数据采集工作,从而提高采集效率。这种“游击战术”不仅让爬虫在数据采集的战场上如鱼得水,更让数据的质量和数量得到了双重保障。
保护隐私安全的守护神在网络世界中,隐私安全是每个互联网用户都关心的问题。对于爬虫开发者而言,使用爬虫IP不仅可以隐藏爬虫程序的真实IP地址以保护自己的隐私安全,还可以降低被反制的风险。这种“隐身术”让爬虫开发者在数据采集的过程中更加游刃有余地应对各种挑战。
三、爬虫IP的实战策略 选择合适的爬虫IP提供商在选择爬虫IP提供商时,我们需要综合考虑多个因素。首先是IP质量,包括IP的匿名程度、稳定性和速度等。高质量的IP能够确保爬虫的稳定运行并提高采集效率;其次是IP数量,对于需要进行大规模数据采集的任务而言,拥有大量IP资源的提供商无疑更具优势;再次是价格因素,不同的提供商价格可能有所不同,我们需要根据自己的预算和需求做出合理的选择;最后是服务支持方面,良好的服务支持能够在出现问题时及时为我们提供帮助确保爬虫程序的稳定运行。
配置爬虫程序使用爬虫IP在配置爬虫程序使用爬虫IP时我们需要根据具体的编程语言和爬虫框架进行相应的设置。以Python的requests库为例我们可以通过以下步骤来配置代理服务器:首先从爬虫IP提供商处获取可用的IP地址和端口号;然后在爬虫程序中设置代理服务器将IP地址和端口号填入相应的参数中;
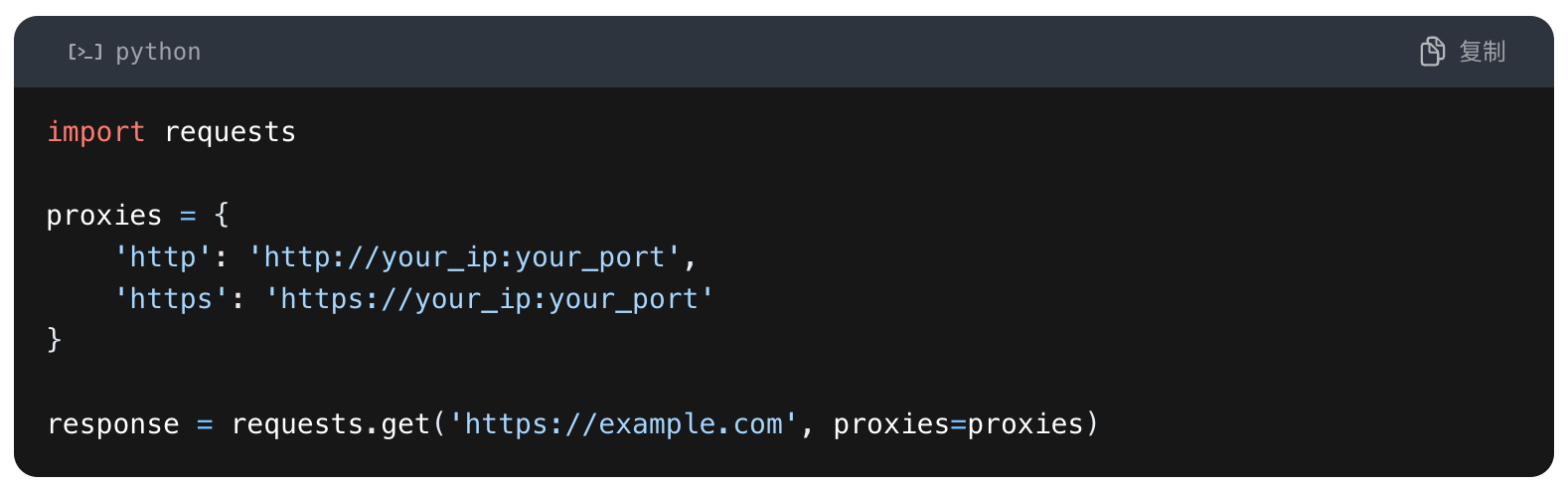
最后通过访问一些网站来测试代理是否生效以确保代理设置成功。
注意事项与合规原则在使用爬虫IP进行数据采集时我们必须严格遵守法律法规和道德规范不得进行任何非法的数据采集活动。同时我们还需要遵守目标网站的规定避免因为违反规定而被追究法律责任。此外我们还需要合理控制访问频率避免因为过于频繁的访问而被目标网站识别为爬虫行为而被封锁。通过遵守这些合规原则我们可以确保数据采集的合法性和安全性让爬虫IP在数据采集的战场上发挥更大的作用。
结语
总之爬虫IP在网络爬虫中扮演着至关重要的角色。通过深入了解爬虫IP的分类、作用以及实战策略我们可以更好地利用爬虫IP来提高数据采集的效率和成功率。同时我们还需要时刻关注法律法规和道德规范的动态确保我们的数据采集活动始终在合法合规的框架内进行。只有这样我们才能在数字化时代的浪潮中乘风破浪勇往直前。